Для тех кто не знал. Или знал, но забыл.
1)
Какие документы переиндексировались после изменений можно узнать запросом с помощью недокументированного оператора idate.
idate позволяет ограничить набор документов теми, которые обновили дату индексации,
date убирает документы, которые впервые попали в индекс (новые документы). Разница дает документы, которые были, но переиндексировались.
2)
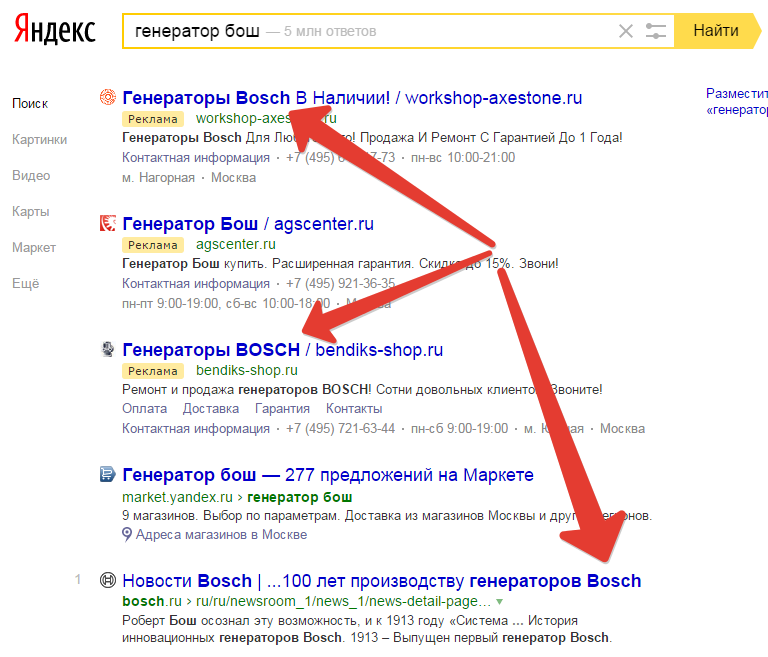
Смотрим выдачу без СПЕКТРа, так как СПЕКТРальные места занимаются по отдельному алгоритму ранжирования. Полезно для оценки конкуренции, например.
Для просмотра без СПЕКТРа достаточно добавить в конец запроса собаку @.
3)
Подсветка без синонимов. Подсветка - это еще не синонимы. Точнее, не только синонимы, но и аналог LSI в Яндексе. Поэтому надо для себя эти две вещи разделять в подготовке ТЗ для копирайтеров. Синонимы хорошо использовать, как замену вхождений, остальная подсветка идет для доработки текста ради повышения его качества.
Выдача с синонимами. Добавляем в адресную строку &nosyn=1 и получаем без синонимов.
Пример того, что остается, когда вычеркнуты синонимы.
Переносим синонимы в отдельный список и работаем над ТЗ копирайтеру.
4)
Проверка на аффилиат. Удивительно, как много людей не знает о том, как это делать. Аффилиат - позапросный алгоритм, накладывающий ограничение на вывод двух сайтов в одной выдаче. Т.е. по одним запросам ваши сайты могут иметь аффилиат, а по другим нет.
Когда у вас несколько сайтов в смежных нишах, вы хотя бы в курсе, что на них может быть наложен аффилиат и можете контролировать это параллельным съемом позиций по продвигаемым запросам. Однако, поиск может наложить аффилиат на несколько сайтов ошибочно. Обычно это происходит, когда сайты пересекаются по адресной или хостовой информации, реже - по донорам.
Вот так выглядит выдача с аффилиатом по двум сайтам.
Шестое место занимает один из двух сайтов. Но если мы его исключим из выдачи, то получим второй сайт на восьмом месте. Но распределение мест здесь не обязательно такое (что склеенный ниже). Иногда склеенный сайт значительно выше, чем тот, что на выдаче и это прям беда-беда, так как аффилиат не снимается без доказательств, что это разные юрлица и/или торговые марки.
В менее очевидных случаях, когда непонятно, на какой сайт склеили ваш, приходится последовательно перебирать сайты один за другим, пока не найдете тот, кто послужил причиной вылета вашего сайта из поиска. Тогда уже пишем письмо платонам на расклейку. Расклейка занимает после ответа платонов примерно от 3 до 7 недель. Не факт, что позиции вернутся к изначальным, кстати.
5)
Проверка на склейку по сниппетам. Часто ошибочно за аффилиат признается склейка по сниппетам - исключение сайтов из выдачи за схожий контент. Для склейки необязательно, чтобы ваш сниппет полностью совпадал с чужим. Есть алгоритм, который вычисляет степень схожести и производит исключение. Выглядит действие данного алгоритма как пропадание сайта из выдачи.
Чтобы проверить наличие склейки, добавляем в конец адресной строки запроса &rd=0
Если сайт после такого запроса возвращается в выдачу, то на нем склейка по сниппетам, а не аффилиат. С каким сайтом произошла склейка, выявляется так же методом последовательного исключения сайтов из выдачи, как и в п.4). Находим, добиваемся различий в сниппете, иногда и в контенте сайта. После этого пишем платонам. Расклейка занимает также от 3 до 7 недель после положительного ответа об ошибке.
6)
Проверка на то, проиндексировало ссылку с уникальным анкором - по тому, попал ли анкор в анкор-лист по проекту.
Эту проверку спалил Сергей Людкевич относительно недавно, но не поясняя практическое применение. Работает она так.
Ограничиваем выборку оператором inlink, а внутри нее отбираем по конкретному урлу. Если к этому урлу фраза попадает в анкор-лист, то выдача будет непустой. Можем считать, что поиск проиндексировал ссылку с таким анкором и как-то ее в ранжировании учитывает.
Ну, и в конце
хак по бесплатной проверке индексации у сайтов с числом страниц от ста тысяч в индексе. Понятно, что проверка через операторы запросов упрется в количество лимитов или будет стоить значительных денег в антикапче. Но можно сократить число проверок до подозрительных кластеров, если правильно сделать адресную структуру.
Панель вебмастера показывает число страниц в индексе с точностью до папки. Бьем структуру так, чтобы число документов, закрытое в адресе /metkoy в ЧПУ было нам точно известно (по карте или по внутренним счетчикам материалов). Т.е. допустим, есть новости. Закрываем их /newslist/ - точно знаем, что новостей у нас 1240 штук. В панели вебмастера смотрим число в индексе, сверяемся - принимаем решение о полной проверке, если число реальное и в индексе сильно отличается.
Можно так раздробить структуру при желании, что выявить кластер с проблемной индексацией не составит труда даже беглым взглядом.
Удачи в продвижении ваших сайтов!
Заказать продвижение:
http://remarka.info/
Самому научиться продвигать:
http://seohowto.ru/course/